 微信登录
微信登录 我要订阅
我要订阅






14日,记者从中国科学院西北高原生物研究所获悉,该研究所张同作研究员联合青海大学魏青副教授等团队,成功组装了藏羚染色体级别的基因组,首次获得藏羚染色体水平的高质量基因组和注释信息,为藏羚的适应进化遗传机制、保护遗传学研究及进一步探索物种迁徙行为的遗传机制提供了重要基因组资源。相关结果发表在《自然》旗下综合性科学期刊《科学数据》上。

藏羚基因组的组装和注释结果。受访单位供图
张同作向记者介绍,藏羚是世居青藏高原的典型反刍动物,平均分布海拔为3250米至5500米之间,是藏羚属唯一物种。19世纪中期至20世纪初,非法盗猎使藏羚的种群数量下降了约90%,2000年藏羚被IUCN红色濒危物种名录评估为濒危物种。经过30多年的保护,藏羚的种群数量恢复到了20多万只,世界自然保护联盟对其评级从濒危降为近危。
藏羚不仅是世界上分布海拔最高的反刍动物之一,也是青藏高原唯一具有长距离迁徙行为的物种,是研究高海拔适应性机制和迁徙行为的良好模型。然而迄今为止,公开数据库中仍缺少藏羚高质量的染色体水平基因组,严重限制了基于遗传特征解析其物种适应、进化及种群生态相关工作的开展。
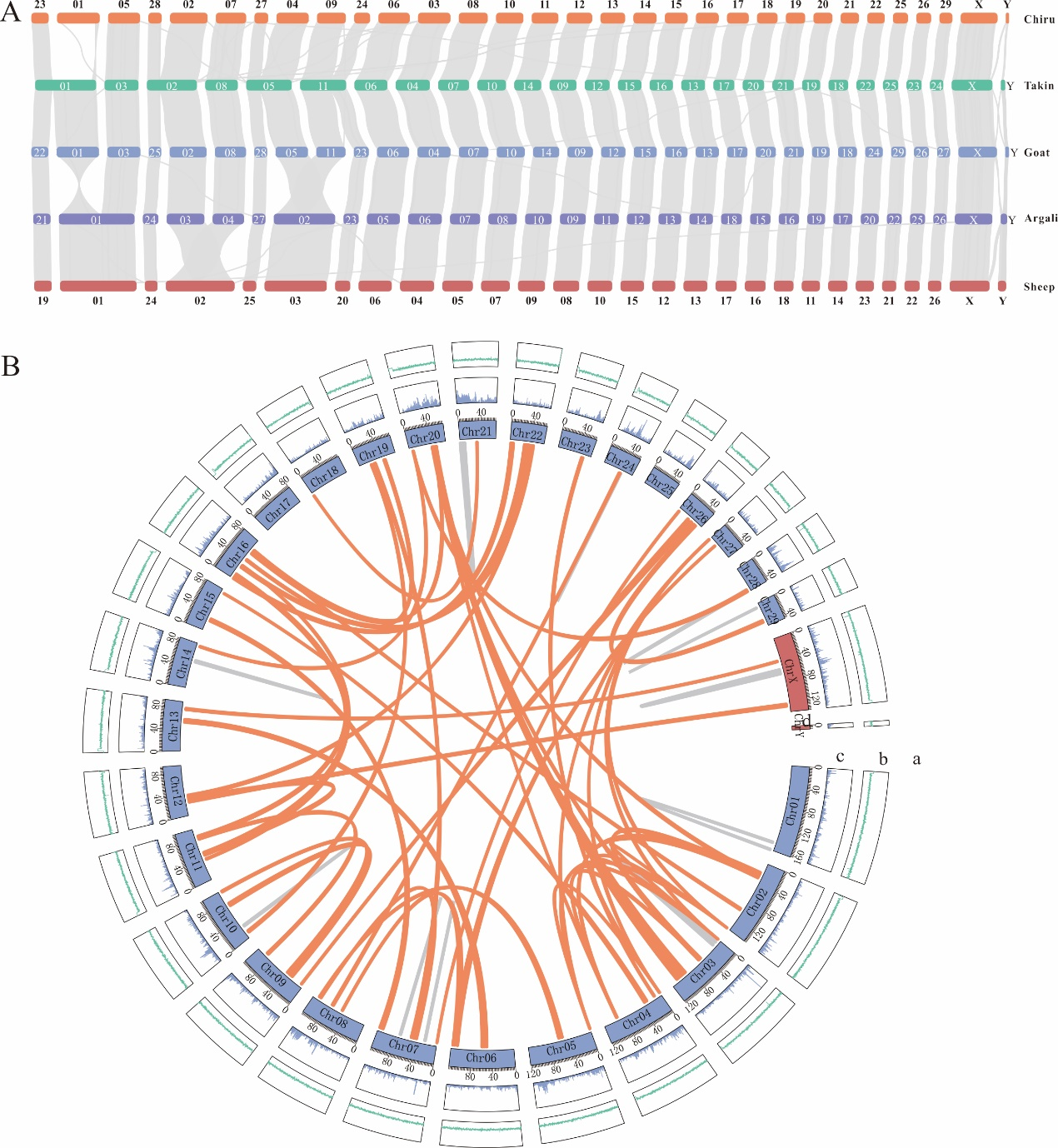
藏羚的基因组特征及与近缘物种之间的基因组共线性结果。受访单位供图
基于PacBio HiFi三代基因组测序、Hi-C测序和DNBSEQ-T7二代基因组survey测序三种测序技术,研究团队成功组装了藏羚染色体级别的基因组。张同作表示,数据评估藏羚基因组BUSCO得分为98.2%,平均QV值为70.14,表明组装的连续性好,完整度和准确性高。基于EDTA和RepeatModeler从头预测的藏羚基因组中重复序列注释结果表明,藏羚基因组重复序列主要由SINEs、LINEs、LTRs 和DNA transposons四种类型组成,序列总长度为1.65Gb,占基因组的52.47%;基于蛋白同源预测、蛋白从头预测和深度学习等多种策略,在藏羚基因组上共注释到28330个功能基因。
